This article provides an overview of Retrieval Augmented Generation (RAG) trends, with a specific focus on how ExtractorAPI can be utilized as a tool to build and update enterprise data stores.
RAG Overview
Retrieval Augmented Generation (RAG) is increasingly recognized as an effective methodology for enhancing Large Language Model (LLM) responses with contextually relevant information. This information can be proprietary or specific to a particular task, such as retrieving information about sports betting lines.
RAG has proven particularly useful in enterprise and business contexts, where AI teams aim to ensure that end-users receive accurate information from their LLM applications, along with an audit trail detailing how an answer was derived.
The typical steps in a RAG process are:
1. Retrieve Information: Source relevant data.
2. Pass Information to the LLM: Transfer the sourced data to the LLM.
3. LLM Analysis: Request the LLM to read the information, answer questions, and perform analyses.
4. Result Verification and Distribution: Verify the results, link to sources, and pass them to the end user.
5. Repeat the Process: Apply these steps across various information sources and analyses.
When translated into a set of tools and a flow diagram, the process is typically represented as shown in standard diagrams (credit to AIMultiple on this one)
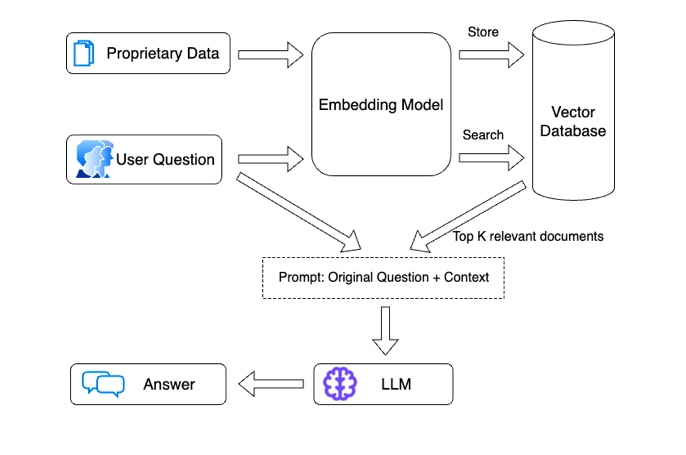
Increasingly flexible, the RAG stack now supports various development platforms, allowing integration with multiple LLMs and Vector DBs. Vectara, for instance, provides an advanced representation of this stack, illustrating the tools currently in use.
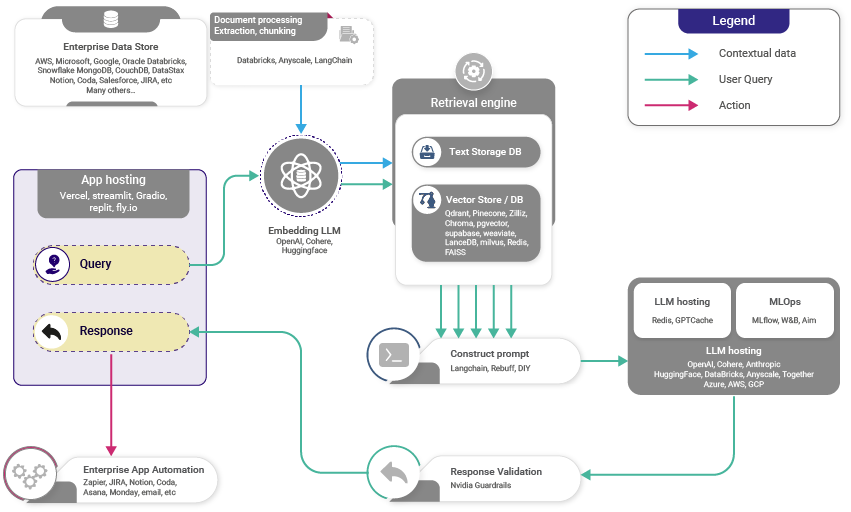
As you can see, the above diagrams assume that there is an existing enterprise data store of information that you want to leverage for a RAG use case. This might be the case, but it also misses out on the fact that development teams may be looking to include new information on a daily basis whether public or private. It's important to have a simple and cost effective tool to do so, and that is where ExtractorAPI can be a huge asset.
Enhancing Your Data Store with ExtractorAPI
ExtractorAPI plays a crucial role in enhancing enterprise data stores. It enables development teams to pull clean JSON responses from websites or local PDF documents, which can then be stored within internal databases.
Consider a scenario where new PDFs are saved daily into a company's record store, and these need to be referenced for tasks such as analyzing healthcare M&A trends. Before these files can be chunked, cleaned, and embedded for later reference, there's a need for a pipeline to extract data from them. With a simple POST request using ExtractorAPI, text data can be extracted for downstream processing. Here's an example using a Bain M&A report:
python Copy code
import requests endpoint = "https://extractorapi.com/api/v1/pdf-extractor?apikey=YOUR_API_KEY&page_num=0" r = requests.post(endpoint, files=dict(file="REAL FILE TO EXTRACT")) print(r)

In another scenario, there may be a need to stay updated with news on a specific subject. The ExtractorAPI can swiftly pull text data from any publicly available site. For instance, to gather information from AIMultiple, a simple GET request can be made:
import requests endpoint = "https://extractorapi.com/api/v1/extractor" params = { "apikey": "YOUR_API_KEY", "url": "example.com" } r = requests.get(endpoint, params=params) print(r.json())

Conclusion
Developers can integrate these ExtractorAPI calls into their RAG development pipelines, enabling enterprises to maintain a constantly updating stream of information flowing into their datastores. This ensures that employees have access to the latest and most relevant information for their tasks. Try ExtractorAPI today to enhance your RAG capabilities.